


TO IMPROVE THE EFFICIENCY OF I/O BOUND SYSTEMS, one of the first things we want to look at is memory. With better use of memory and caching, we minimize the activity on the disk drives. The disk drives are the slowest things on the box - to physically go to the disk to retrieve data takes far longer than getting data that's already in memory or in the program and accessible to the CPU. There are techniques for getting the right data for your application pinned into memory so that you can minimize disk activity. Also, you can reorganize data in a sequence that's more appropriate for your application that just a chronological sequence.
Let's focus on improving areas within your applications so that they request less I/O. Your system will be able to accomplish the same tasks, but will need less resource. For example, you might have an application that is CPU-bound, has bad response time, memory faulting, high disk actuator arm activity, long duration of batch jobs, or slow web requests. Ninety percent of the time, you can tie these issues back to an application that's requesting more I/O than it needs to - it's probably reading 1,000 records to select 10. If the application had only read 10 records, it would have been done a fraction of the time, and used a fraction of the resource.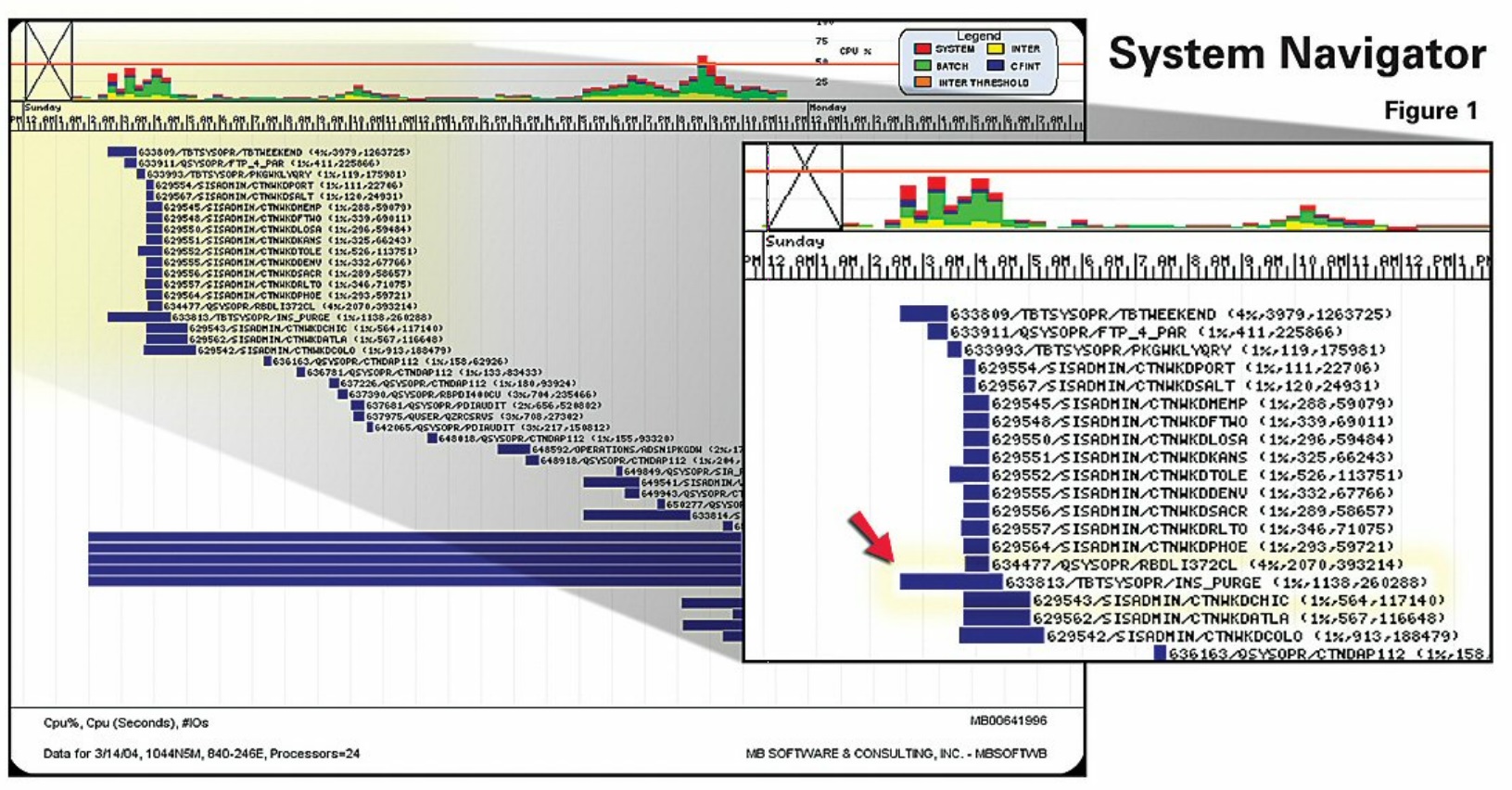
Is your system actually I/O-bound?
The first step is to validate that your system is, in fact, I/O-bound; a good clue is an underutilized CPU. You might have long-running batch jobs, high memory faulting, high disk actuator arm activity, and your users complaining about poor response time, yet the CPU - one of the most expensive resources on the box - is only partially used.
In this example (Figure 1), we're characterizing CPU use from 0 to 100 percent over a 24 hour time scale. As you can see, the CPU is barely used: 2 percent up to 15 percent. Even at peak times it's just barely getting above 50 percent. But, notice a purge job (633813/TBTSYSOPR/INS PURGE) starting at 2:30 in the morning and running to 4:30 - why did that job run for 2 hours? Why wasn't it done quicker? Not because the system was CPU-bound, but averaging 1 percent of the CPU, but did an excessive amount of physical I/O; the disk arm went to disk to retrieve data 260,000 times.
Any application that has an excessive amount of I/O with low CPU use is likely I/O bound. There may be long-running batch jobs or poor interactive response time during the day. Also, jobs may be running continuously, interfacing data between systems. Web requests may be coming into continuously running jobs, starting and stopping threads each time a request hits the web server.
Identify Files with the Highest Physical I/O
Once you've convinced yourself that the system is in fact I/O-bound, you want to start digging down into the data to identify specific files with the highest physical I/O. Here, the difference between physical I/O and logical I/O is an important distinction.
Logical I/O is, logically, what the program is doing. It's going out and reading a record, or perhaps 1,000 records. If you have poor blocking or poor caching algorithms, you might go to disk a thousand times, once for each record. But if those records were already cached into memory, or it took just one physical read to get them cached into memory, one physical I/O would accomplish 1,000 logical I/Os.
There are several techniques that will help you achieve this. One is using the Set Object Access (SETOBJACC) command. You have to use it appropriately; you don't want to try to pin a terabyte file into memory. However, a lookup table with a thousand records in it that's used excessively within your application might be the perfect file to use this command on.
Depending on your situation, the right solution might be to load data into internal program arrays. If you have an excessively accessed date calculation routine that's going out and opening files, doing a lot of I/O, determining a result, closing all those files and returning the result, you have a problem. If the program is physically reading data from disk each time a date routine is called, that's an issue, as is the opening and closing of those files. That routine could be called 60,000 times a minute in a batch job, or 100,000 times an hour throughout the day by your interactive or web applications. Dealing with that data internally may be a better solution.
Whatever your industry is, you probably have transaction history files that have years' worth of data in them, such as General Ledger or patient history files. Yet the most frequently accessed data is the most current data. Look at your transaction history files and purge the old data, or move it out of your open transaction files and into separate history files. For example, accounting users looking to figure out why the books aren't balancing at month end are looking at last month's transactions. They're not looking at seven-year-old data. Of course, you want to keep the data, but not in that more heavily accessed file.
Make sure you're building better logical files while deleting old ones that you don't need. Prevent full table scans where possible, whether that full table scan is occurring through SQL, RPG, COBOL, or even CL. Full table scans or access path rebuilds are a lot of I/O that just doesn't need to occur if the application were doing its job more efficiently.
Here's an example (Figure 2) looking at disk activity statistics across a system. You see that 57 percent of the physical reads across the whole system in a 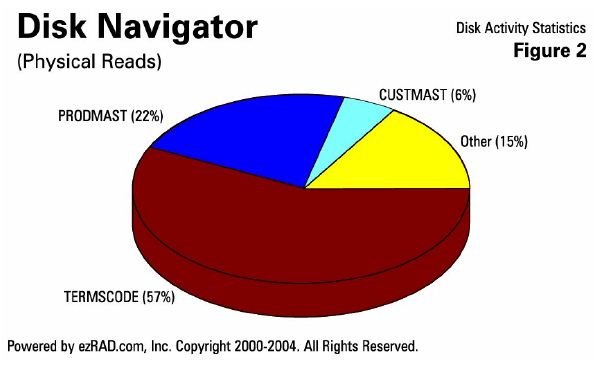 24-hour period of time are occurring over one file called TERMSCODE. This is a good example of a file that you'd want to use the above technique on, such as SETOBJACC. You have thousands of files on your system and three files are responsible for 85 percent of the physical reads. If this is the case in your environment, you'll want to deal with these files appropriately. This is just one level of looking at data - it's good to look at the high level first and drill down appropriately depending upon what you find at the higher levels.
24-hour period of time are occurring over one file called TERMSCODE. This is a good example of a file that you'd want to use the above technique on, such as SETOBJACC. You have thousands of files on your system and three files are responsible for 85 percent of the physical reads. If this is the case in your environment, you'll want to deal with these files appropriately. This is just one level of looking at data - it's good to look at the high level first and drill down appropriately depending upon what you find at the higher levels.
Tune Database, Avoid Access Path Rebuilds
Identify the files that are most heavily hit and avoid full table scans, reading a file from top to bottom. This usually isn't being done intentionally, but it's extremely inefficient nonetheless. For example, your operating system or database server can be reading a million records, checking every record to see if the order status is OPEN so that you can generate an Open Order Report. But if you have the proper index, permanent logical file or access path keyed by order status, the database can use that index rather than do a full table scan or full access path rebuild. This will significantly reduce the I/O in your system and free up the I/O bottleneck.
Bear in mind, it's ok to do a full table scan or temporary access path rebuilds on small tables. In some situations, that is the proper approach - say you're doing an Open Query File (OPNQRYF) or an SQL select over a hundred records to sort data at the beginning of a three-hour batch job. It's quick, and it's not significant. But if that same process is occurring over large files, or if it's occurring repeatedly throughout the job or throughout the day interactively over small files, it can become a problem.
I believe we were all taught years ago that you didn't need a database administrator on this platform. I agree that you don't necessarily need a full-time database administrator, but you can't completely avoid the issue of basic database administration. If you do, you'll end up with an I/O-bound system, and lots of access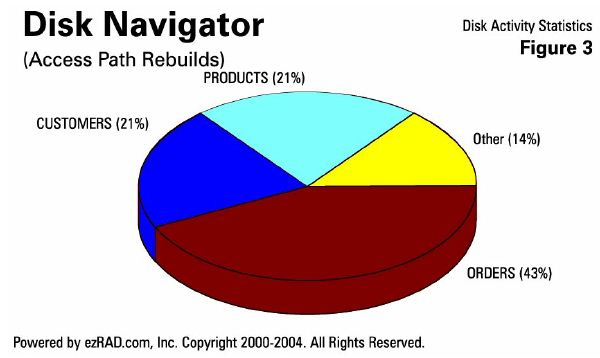 path rebuilds and full table scans that are occurring unnecessarily. With better techniques, you can dramatically reduce the I/O need - not by just 20 percent, but by 90 percent on specific jobs and up to 70 percent over the whole system.
path rebuilds and full table scans that are occurring unnecessarily. With better techniques, you can dramatically reduce the I/O need - not by just 20 percent, but by 90 percent on specific jobs and up to 70 percent over the whole system.
Here's an example (Figure 3) showing access path rebuilds across the whole system. Three files, ORDERS, CUSTOMERS, and PRODUCTS, are responsible for all but 14 percent of the access path rebuilds occurring on the system. The ORDERS file alone accounts for 43 percent of all access path rebuilds, yet there are thousands of other files accessed on the system.
Identify Specific Culprits & New Logicals
Let's identify the users, the jobs, and the programs that are causing unnecessary I/O on your system. Whether it's batch or interactive green screen processing, ODBC or JDBC; whether it's coming through a client/server application or coming through a web browser, it doesn't matter. It's all the same performance issue. The further you get away from the green screen, the more network response time becomes an issue, especially when you're flooding 1,000 records over a pipe to a client/server application that's only going to show 10 of them. Let's identify the specific jobs and users, the actual I/O by file and by program that's responsible for the unnecessary traffic. You need to determine what logicals to build,  what lines of code, subroutines or programs are the culprits so that you can take action to improve the efficiency of your I/O-bound system.
what lines of code, subroutines or programs are the culprits so that you can take action to improve the efficiency of your I/O-bound system.
This chart (Figure 4) shows 50 billion unnecessary I/Os occurring within your application software. All of these records were read by queries, but they weren't selected. And while it's not specifically shown here, these billions of records are probably being read in a 24-hour period that didn't need to be read, 39 billion of which are because of one file. If you built one or two indexes over this one file you could reduce the I/O on the system by 50 percent. You want to find the quick fix. Focus on the 80/20 rule and find the quickest thing that you can do that's going to give the biggest benefit.
Avoid Simple CL Programming Issues
Using the Copy File (CPYF) command in a CL program with SELECT/OMIT criteria to extract one day's worth of data from a huge history file is a very simple and neat technique, but it doesn't use an index. The data gets put into a work file in QTEMP so that QTEMP file can sort the data with its key list. This is an inefficient technique.
There is a very simple fix for this - simply replace the CPYF command with an Open Query File (OPNQRYF) command that has the selection criteria on it. Then use a Copy From Query File (CPYFRMQRYF) command that uses that open data path and copies the selected records into the file in QTEMP. You don't have to rewrite your application. You can replace one line of old code with two lines of code and it can dramatically improve your system, especially if this issue is occurring repeatedly throughout the day. It's an easy technique to significantly limit the I/O need of this application. However, maybe you're more comfortable doing that SELECT/OMIT with RPG, COBOL or SQL. Either way, the goal is to reduce unnecessary I/O. Using the work file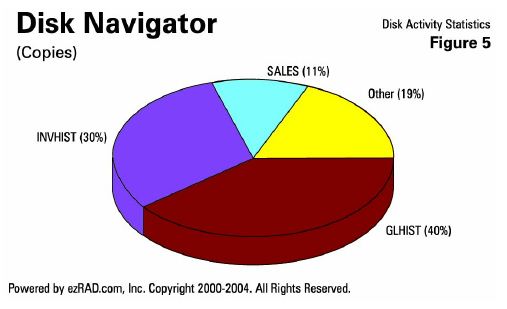 s in QTEMP with key lists to sort data is a great technique, as long as you get that data in there efficiently - full table scans and access path rebuilds are rarely the right answer.
s in QTEMP with key lists to sort data is a great technique, as long as you get that data in there efficiently - full table scans and access path rebuilds are rarely the right answer.
Here's an example (Figure 5) showing how many CPYF commands are occurring across a whole system in a day. The General Ledger transaction history file (GLHIST) accounts for 40 percent of all of the CPYF commands that are occurring on your system. Inventory transaction history (INVHIST) accounts for 30 percent, and the SALES detail file accounts for 11 percent. The other thousands of files are Other - only 19 percent of the total. You can quickly see where issues are.
Prevent Unnecessary Opens and Closes
An application that's constantly opening and closing files or initiating and terminating batch jobs can cause unnecessary overhead. Interactive sessions starting and stopping every time someone presses an attention key is equally inefficient. Triggering new jobs every time someone accesses a web page contributes to poor web response time. Initiating and terminating separate SQL requests with lots of SQL-related overhead, just to go get one record, is a fundamental issue as well. Instead, you should keep the files open and reuse the open data paths, simply moving a record pointer around. Repetitive opening and closing, initiating and terminating is usually unnecessary, and is being done for simplified programming in most cases; it's not being done for optimum performance. A file left open all day is a good thing. It gets more difficult when you're dealing with a web browser or client/server application, but leaving files open and jobs active is far better than constant initiation and termination.
It's important to share open data paths properly. You can always share open data paths within an application, know your record pointers and be able to rely on them. Simply going out and changing all your data files to share open data paths wouldn't be a good idea. Using shared open data paths where possible avoids that op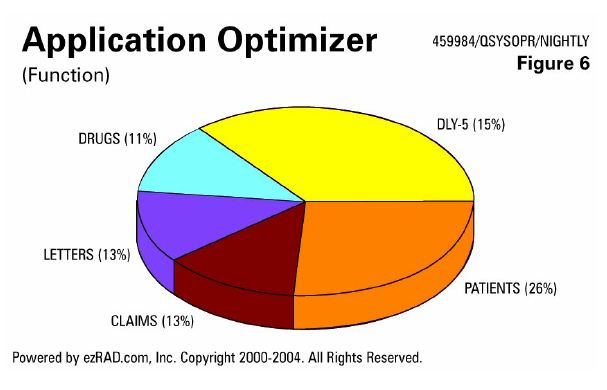 ening and closing of another access path unnecessarily. Knowing the difference between a RETRN and a SETON LR is extremely important. It allows for user-controlled opening and closing of files rather than letting RPG do it, and it lets you leave programs in memory.
ening and closing of another access path unnecessarily. Knowing the difference between a RETRN and a SETON LR is extremely important. It allows for user-controlled opening and closing of files rather than letting RPG do it, and it lets you leave programs in memory.
Here (Figure 6) we're looking at opens and closes. Again, identify the files that are most problematic.
Identify Specific Job and User Culprits
It's important that you get hardware and software in sync. If you have one of the older server models, where 80 percent of the CPU can be used for batch and only 20 percent can be used for interactive, you don't want to run an application that's 80 percent inter-active. The same thing applies to memory and to disk activit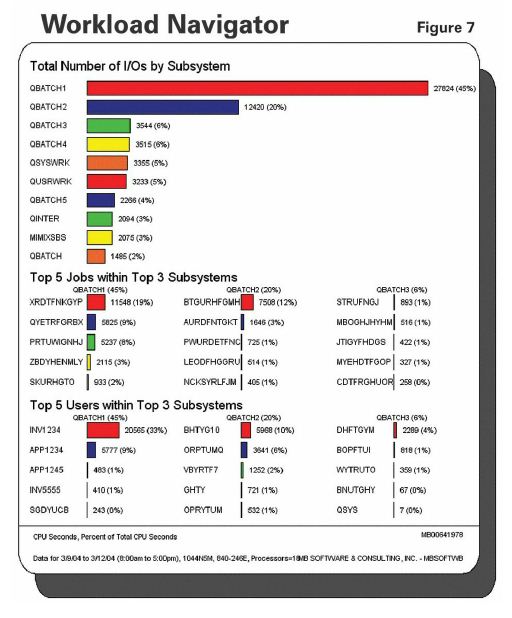 y. If you have an excessive high-I/O application, you want to make sure you have hardware that can handle that I/O. There are a few ways to do this: you can purely work on the hardware, you can purely work on the application to get it in sync with the hardware, or you can do both. If you do both, you're going to have optimum performance at a fraction of the price.
y. If you have an excessive high-I/O application, you want to make sure you have hardware that can handle that I/O. There are a few ways to do this: you can purely work on the hardware, you can purely work on the application to get it in sync with the hardware, or you can do both. If you do both, you're going to have optimum performance at a fraction of the price.
Many environments are making code changes, system management changes or database tuning changes for specific business needs. You should make performance one of those business needs, where it makes sense. Hardware upgrades will clearly help, as long as it's the right kind of hardware upgrade. You don't want to be upgrading CPU or getting more CPUs or faster ones when you have an I/O-bound system that's barely using the CPU it has. Spending that money on memory, faster disk drives, newer disk drives with better caching algorithms would be a better approach.
This chart (Figure 7) shows data collected from 8am to 5pm Monday through Friday, ranking physical I/O across the whole system. This is a great chart for figuring out what the key jobs and users are. As you can see, one batch subsystem is responsible for 45 percent of physical I/O. One user is responsible for 33 percent. One job is at 19 percent, and a second is at 12 percent. Focusing on these jobs and drilling down into them would be a great opportunity, and a way to use the 80/20 rule. Let's focus on them, do what we can from an application, database tuning and systems management standpoint to reduce the needs of these jobs. Fix everything else with hardware.
Find Specific Operating System Functions
You want to find the specific operating system functions that are being performed and are consuming the resource under the covers. If you see the programs called QQQIMPLE or QSQROUTE being high in the data, that's an indication of a query- or SQL-related issue that can be addressed with proper indexing.
You should eliminate full table scans or constant initiation and termination of thousands and thousands of SQL requests.
You should understand the difference between the functions called QDBGETSQ and QDBGETKY - the sequential reading of data vs. the random reading of data. If you see a job, an interactive session, or a web request that's spending 90 percent of its time sequentially reading data, that means it's spending less than 10 percent of its time randomly reading data, doing updates, and writing records. It's not reading data very efficiently, and 90 percent of all issues are applications that aren't reading data efficiently.
You want to trace operating system functions back - to the application program, to the lines of code, to the subroutines - so you can figure out better ways of accomplishing the same task. We're not talking about rewrites, but simple changes that just take a slightly different approach to get those records more quickly. Y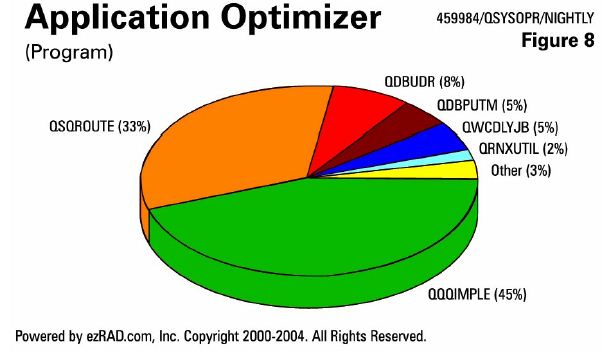 ou always need to weigh the cost vs. the benefit when you're making any kind of a change. Make sure that you're making the right business decision - you want to find the quick fixes, the easy changes, whether they're code changes, systems management, database tuning, or hardware-related.
ou always need to weigh the cost vs. the benefit when you're making any kind of a change. Make sure that you're making the right business decision - you want to find the quick fixes, the easy changes, whether they're code changes, systems management, database tuning, or hardware-related.
Here's an example (Figure 8) of a nightly job stream. 45 percent of its duration is spent in the operating system function QQQIMPLE, 33 percent in QSQROUTE. There is a significant amount of time in SQL-related activity that could be addressed with a couple of new permanent logical files. When this is a nightly process that's running for 6 hours, and you see it starting to creep into the morning, causing systems to not be available to the end users on time in the morning, it's time to make some changes.
Analyze Application Program Efficiency
After exhausting all database and hardware tuning opportunities, let's focus on the application programs. If a program is spending 75 percent of its time finding data, it's not very efficient. It should've found its data quickly and acted on that data. Get that application to spend less time searching and sorting and you'll free up that I/O bottleneck. Allow the CPU to be used effectively - it should be performing the calculations, doing the updates, adding new records, and deleting records - not reading, reading, reading, reading, looking for the records to process.
Here's (Figure 9) another nightly batch job. It's building work files and sorting data most of the time. Very little time is spent updating sales, printing reports, generating transactions or loading data. Use the proper keyed file sequence. Create an index based on key fields such as account number and customer to give t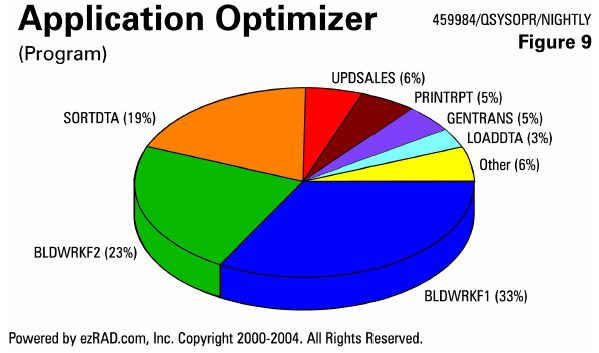 hat WHERE clause what it needs to reduce the million records down to the one record or the ten records as quickly as possible.
hat WHERE clause what it needs to reduce the million records down to the one record or the ten records as quickly as possible.
Dynamically sorting 10 records in memory is going to be quick and efficient. You don't want the operating system to take forever to scan a million records to find the 10, and then use an index to sort those 10 records. It could've sorted the 10 records on its own quite efficiently. It needed a permanent index to go get the 10 out of the million as quickly as possible.
Here's yet another example of this efficiency (Figure 10). After seeing data from more than 1,500 systems over 10 years, one can quickly determine that this is a top issue. ORDERDTL, ORDERHDR, CUSTMAST, PRODMAST, and REPRTWRK are all open for input. The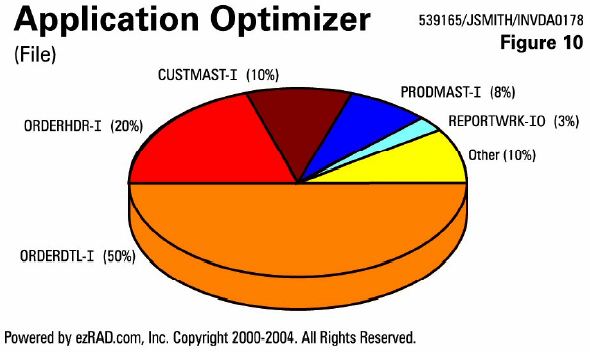 actual work - taking the records, writing them to the work file and generating a report or doing an invoice update or whatever we're doing here - accounts for only 10 percent of the work.
actual work - taking the records, writing them to the work file and generating a report or doing an invoice update or whatever we're doing here - accounts for only 10 percent of the work.
Find Procedures within Code Causing Issues
You want to find within the code where these issues are occurring. Find the procedures, the subroutines, the functions, the modules, the service programs, the COBOL, RPG or CL programs, the Java routines or the C code. If you know what the issue is within the code, you have all kinds of options; however, if you don't know what the real issue is, you're fixing the wrong things. You're making changes, but they're not really solving the problem because they weren't the right changes to solve the I/O bottleneck. Whether you actually change code or not, knowing within the code where the issue is can help you do things outside of the code that will give it significant benefit. In those cases where you do have code and you do change or create your own code, rewrite just a specific routine, tax calculation routine, inventory-lookup, quantity-on-hand or available-to-promise routine is the issue, focus on it.
Most of the time you don't need to rewrite anything - you're looking for quick fixes. But perhaps you have a complex old routine from 15 years ago that does need to be rewritten. Rewrite that routine, not the entire application. As long as you've identified the right routine, it might be worth it. Again, weigh the cost vs. the benefit.
Pre-summarized data is a great thing as well. For example, re-summarizing sales data constantly 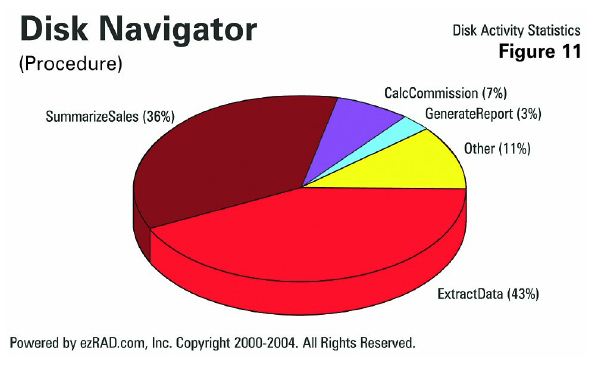 throughout the day that only gets changed in your nightly batch job stream isn't that efficient. Instead, when that data gets updated at night, add a step to the process: summarize the data into a new table that those daytime applications can now use. Daytime users are now accessing static data very efficiently - that 500-region sales summary file vs. 50 million records that were constantly being re-summarized repeatedly throughout the day. Go ahead and leave the application the way it is, but pre-summarize your data at the end of the nightly processing. Even if that same job runs every hour, it would be better than 1000 times a day - inefficient queries over small sets of data aren't a performance issue. Inefficient applications or inefficient use of resource over large sets of data is where the issues come in. If you're after open transactions, you want to process only the open transactions - never let a record pointer even navigate by those 7-year-old transactions.
throughout the day that only gets changed in your nightly batch job stream isn't that efficient. Instead, when that data gets updated at night, add a step to the process: summarize the data into a new table that those daytime applications can now use. Daytime users are now accessing static data very efficiently - that 500-region sales summary file vs. 50 million records that were constantly being re-summarized repeatedly throughout the day. Go ahead and leave the application the way it is, but pre-summarize your data at the end of the nightly processing. Even if that same job runs every hour, it would be better than 1000 times a day - inefficient queries over small sets of data aren't a performance issue. Inefficient applications or inefficient use of resource over large sets of data is where the issues come in. If you're after open transactions, you want to process only the open transactions - never let a record pointer even navigate by those 7-year-old transactions.
Here's an example (Figure 11) of looking at data by procedure. Again, there's a lot of unnecessary I/O. The extracting of data is 43 percent, and the summarizing of data is 36 percent. The actual calculations, generation of reports and everything else are tiny compared to that inefficient I/O.
Conclusion
Faster disk drives, newer caching algorithms, more memory and bigger processors can help improve the performance of your system. You don't have to make any changes to the application or the database or the way you're managing your system to get improvements, but if you make hardware, application, systems management, and database tuning changes, you're going to get ideal performance out of your system.