


What Every IT Executive, Administrator, and Developer Needs to Know
POORLY PERFORMING systems affect every level of business, from the computer room to the CEO's office. Slow-running processes create frustrated end users and eventually, frustrated customers if the problems continue unchecked. While this fact isn't lost on most companies, how many actually know the cost-effective way to deal with critical performance issues? All too often, IT managers opt for the quick fix, spending huge sums on new equipment that doesn't address the  real problem: poorly performing applications.
real problem: poorly performing applications.
Whether you are an IT executive, a systems administrator, or software developer, the decisions you make in regard to improving system performance have a direct effect on the bottom line. So, before you start shopping for CPU upgrades and additional memory, take a look at your applications - the fix is quite often under your nose, even if you haven't seen it before.
Take a Top-down Approach
The first thing to do is to discover when performance issues are occurring and where they exist. Then, you must focus on the root cause; don't let the symptoms distract you. Spend your time solving the right problems. Many times, we find ourselves 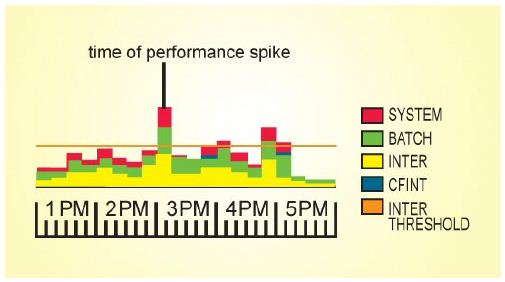
Next, you want to get down into more detail; find the specific jobs that might be causing the issues. Dig deep; look for specific programs, database files, modules, procedures, and even lines of source code that are responsible for the biggest amount of resource consumed on your system. Whether database tuning, system management changes, or application code changes, focus on the root cause.
Very often, we mistake the symptoms of performance issues for the causes. High CPU use, memory faulting, high 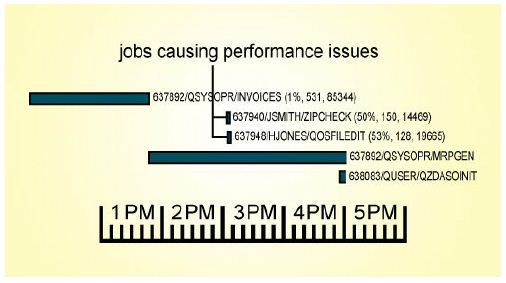
For example, if there's an issue with a date routine that's being loaded in and out of memory 60,000 times a minute, address it. You don't want to spend weeks or months looking 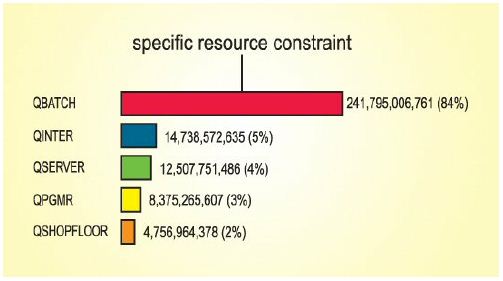
Now, let's look at the role of each IT professional in identifying and solving these performance issues.
Executive Management - Get More From Your Budget
Always look at cost versus benefit. If you have a performance issue and upgrading memory is the right thing to do, go ahead and upgrade your memory. If buying more CPU is the right 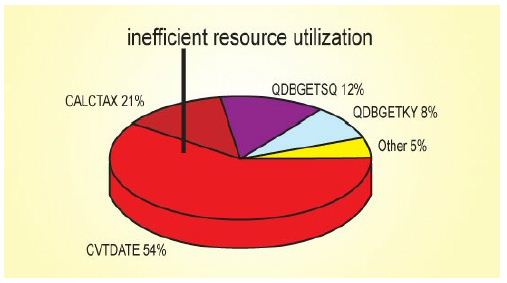
Focus on the root cause. In analyzing more than 1,500 systems over the course of 10 years, we found that 9 times out of 10, performance issues were caused by applications performing unnecessary and excessive I/O. Poor response time, high CPU use, memory faulting, high disk activity, long-running batch jobs, slow client/server and Web requests are all symptoms of inefficient application I/O. Several things can cause this excessive I/O, from the client/server or Web application that's submitting ODBC or JDBC requests that end up being SQL, to the legacy RPG, Cobol, or CL programs with the various techniques that they use for accessing data. Regardless of what technology or programming language you're using, it's the same issue. One language is no more efficient than another in this regard - what matters is how efficiently you're accessing your data.
Focus your staff on fixing the root cause issues rather than the visible symptoms. It's very easy to get consumed with those symptoms - we monitor memory faulting and tune memory, chart and measure average response times per day, and make all these nice charts and tell us what our response time is, whether it's good or bad, and so on. Well, these things are symptoms, not root causes. The cause is something occurring within the application or the workload that could have been done more efficiently.
If you focus on the area under the curve rather than the spike, you will invest your time and money more effectively. A consistent problem is easier to catch than a spike, because it's occurring all the time. It's easy to analyze and resolve compared to a random spike that occurs at different times and for different reasons. Any amount of time you invest in a random issue is usually a wasted investment; it might have gone away on its own, it might have been an anomaly, or it won't occur often enough compared to the things that are happening under the curve.
Understand the cost vs. benefit of your fixes. The quick, easy, traditional thing to do when there's a performance issue is to buy more hardware. You get a quote, see what the upgrade path is, choke on the dollar amount, somehow get the purchase through your budget process, and finally get the bigger hardware that buys you more time. Sometimes, that's even the right thing to do. But more often than not, it's not the right answer from a bottom-line standpoint, and many times buying hardware doesn't even solve the problem.
If only 20 percent of your CPU is used, and your system is I/O bound, what's more CPU going to do for you? You'll simply have more resource sitting idle, perhaps only using 10 percent of the CPU after the upgrade. The issue was an I/O bottleneck; let's address that issue first.
The 80/20 rule is a great rule in life, and not just in performance analysis and application tuning. If 80 percent of the system resources are consumed by 20 percent of the applications, that's a great opportunity to tune workload. If that's not the case - if everything is using one percent, and you don't have a single job, program, user, or database that stands out - it's  time for new hardware. You don't want to fix everything. You don't want to rewrite your application or redesign your entire database. But if one or two things are consuming far more resource proportionally than anything else, that's a wonderful opportunity to focus on a handful of causes. Analyze those things, come up with alternatives, make the improvements, and you will get a huge benefit from the cost that you've invested.
time for new hardware. You don't want to fix everything. You don't want to rewrite your application or redesign your entire database. But if one or two things are consuming far more resource proportionally than anything else, that's a wonderful opportunity to focus on a handful of causes. Analyze those things, come up with alternatives, make the improvements, and you will get a huge benefit from the cost that you've invested.
Better systems management and database tuning are very beneficial, basic things you can do. Whether you have purchased software or you've built the software internally and have a development staff that supports it, there are system management things that you can do differently.
If you don't have source code, you can still tune your database to ensure that your purchased application is performing as efficiently as possible inside your environment. It's very easy for a developer to build that SQL request that asks for the world, forgetting about the consequences on the server associated with that request. Furthermore, the developer is usually creating that application in a very small environment with very little data, and the fastest PC and hardware in the building. Meanwhile, the end user has a very slow system with millions of records in the files - what the developer sees as performing well in a small environment actually performs horribly in the real world.
If you have source code, performance should be a priority when making code enhancements. If it's a business priority to print that invoice properly, and there's a cost associated with not printing it properly, why wouldn't it be a business priority to have good systems performance? Understand the costs involved with each possible fix, and then make the right business decision with all the facts.
Avoid reacting to the latest critical complaint. Save critical resources. Ultimately, the goal is to save resources, which increases the bottom line and increases customer satisfaction. Less time spent chasing issues means more time spent developing new applications and functionality for the end user. Satisfied customers are those that get the application functionality that they need along with the responsiveness that enables them to meet the expectations of their customers.
Systems Administrators - Get More From Your Staff
It's very easy to be reactive in this role, to constantly be working on the latest phone call or the latest complaint from the help desk. It's a difficult mindset to get out of, but it's critical that somehow you do. We need to make sure that we're focusing on proactive monitoring of historical data, then using a top-down approach to find the root cause of performance issues.
Random CPU spikes are difficult to catch, and they're difficult to analyze and resolve. Focus on the things that are occurring consistently, and reduce the overall utilization so that these spikes don't matter. Again: if you spike from 60 to 80  percent, who cares? Nobody. But if you spike from 80 to 100 percent (or to plus signs), we all care. Rather than chasing that random thing that occurred at 10:03 this morning, spend a small amount of time looking at historical data; you might find a quick win - a silver bullet in the data that will reduce your I/O by 20 percent.
percent, who cares? Nobody. But if you spike from 80 to 100 percent (or to plus signs), we all care. Rather than chasing that random thing that occurred at 10:03 this morning, spend a small amount of time looking at historical data; you might find a quick win - a silver bullet in the data that will reduce your I/O by 20 percent.
Analyze historical data. Is SQL performing the same full-table scan or temporary access path rebuild 3,000 times a day? If so, does that cause the area under the curve to be 20 percent higher than normal all day, every day? If so, address that issue. Find the index that needs to be built and use database-monitor data to see where indexes are being advised by the operating system. When the same index is advised 3,000 times a day, it might be time to build a permanent one - especially when that index results in billions of unnecessary I/Os on your system.
Likewise, if the same job is running 250,000 times a week, it isn't going to show up as a spike; it's hidden among thousands of jobs running every day. if you talk to the developer or vendor who wrote the program, they don't see an issue. After all, the job finishes in a second or two; how could that be a problem? Well, it's a huge problem when you total it all up and find that the total CPU consumed and I/O performed by that one-second job running 250,000 times is more resource consumed than by any other process on your system.
It's not uncommon for this type of job to account for 40 percent of the CPU, or 60 percent of the I/O. Submitting a separate batch job, initiating and terminating a quarter of a million jobs, opening and closing 50 files each time, loading and unloading 30 programs in and out of memory each time is extremely inefficient. Instead, leave the job open all week long, leave the programs in memory, leave the files open, and use a record pointer to find data. Implementing a data queue server is a wonderful way to address an issue like this.
Remember to use a top-down approach. Analyze that historical systems management and performance analysis data and focus on the root cause rather than the symptoms. A top-down approach is critical here - the latest help desk call or complaint can steer you in the wrong direction. Look at your overall CPU, I/O, and memory utilization across your system over a 24-hour period of time, and find out where the priorities are from a capacity standpoint. The printing of that invoice may be the priority to your end user, but the culprit might have nothing to do with invoicing.
If specific jobs are consistently causing issues, start at the job level. But when you've isolated the right job, drill down to the data. Is the problem a database issue? What are the programs in this job, and which one is following that 80/20 rule? Which module, procedure, or line of code is responsible for the highest utilization across the whole job?
Simple oversights in the code or application can cause major operational issues, major performance issues, and can increase the cost of ownership of this platform. We're not talking about rewriting applications or redesigning database architectures here. We're talking about basic configuration changes. You might have date routines setting on LR 30,000 times an hour interactively. If you have code, you don't have to go fix every SETON LR - just the ones that are called excessively.
Software Developers - Get More From Your Applications
If you want to get the most out of your applications, you have to focus on the root causes, not the visible symptoms. Developers spend weeks or months digging through code, trying to find what's wrong with a job and why it's running inefficiently.
The problem isn't necessarily the most visible thing. It's usually just a simple thing that should have been insignificant but ended up being the most significant performance issue within the entire process. It's a routine that is invisible to the human eye because it's occurring so rapidly within the jobs. You can't even look at a call stack and see these processes coming and going. But when you do trace-level type analysis and line of code analysis, they're the biggest things. Take, for example, a CVTDATE program. If you have a date routine with a SETON LR, that one line of code can single-handedly cause a job to run for 14 hours versus 20 minutes.
Take, for example, a CVTDATE program. If you have a date routine with a SETON LR, that one line of code can single-handedly cause a job to run for 14 hours versus 20 minutes.
There's only so much the operating system can do to make things efficient. It's not a matter of whether a single opening and closing of a file or a single load and unload of a program in and out of memory is efficient or not; it's the fact that it's occurring 60,000 times a minute. No matter how efficient a single process is, if it occurs 60,000 times a minute, it's not efficient anymore.
Focus on root causes of application performance issues rather than just visible symptoms.
Simple data queue server jobs are often the answer to initiation and termination issues, and triggers are nice as well. However, triggers can be dangerous if not done properly. A dangerous trigger is one that has any kind of complex logic such as SQL statements embedded in it. A trigger should do nothing other than trigger an event - it shouldn't perform the event. It doesn't set on LR, open any files, or run any SQL statements. It just tells a background process that an add, update, or delete occurred on a record. Let the background process go get the record through files that are left open, through programs in memory, and let it do the work in near-real time. A simple data queue server job can cut the number of jobs on a system by 90 percent, and the CPU by 40 percent.
Spend time implementing. Determining that 3 billion records are being read every day to select 25,000 records tells you a great deal, and allows you to focus on the priority issues on the system. Database tuning is critical here: make sure the proper permanent logical files or indexes exist, keyed with the proper key fields in the proper sequence. That way, the SQL requests that are running 25,000 times a day, selecting one record each time, can find and use the permanent logical file, index, or logical view that they need to fulfill that request efficiently. On the other hand, doing full table scans or access path rebuilds 25,000 times a day results in billions of I/O on your system, and horrible response time.
Increase Customer Satisfaction
You've probably heard this a thousand times, but we're all in business because of our customers. The best applications in the world are useless to customers if the applications are not responsive. To your customer, it doesn't matter how wonderful the functionality is if it takes three minutes to navigate between screens.
It's all about cost vs. benefit. Focus on the area under the curve, be proactive, analyze and learn from historical data, and streamline applications when appropriate. Make sure you're fixing the right issues, then test and implement those fixes. We want to improve the quality and responsiveness of applications to the end user through properly performing applications. If you're still having performance issues after your applications are tuned properly, then it's time for hardware.