


The IBM commands 'Display Data Base Relations (DSPDBR)' and 'Display File Description (DSPFD)' can be useful in many ways on your System i and iSeries servers. Whether you are trying to improve the performance of an SQL based application or you are just trying to cleanup duplicate and unused logical files - these are some of the commands to be using.
Most applications revolve around their data that is stored in physical files on your system. Logical files or indexes are used to build, store and maintain alternate views or sequences of this physical data. These logical files can easily get out of control without strong version control and database administration procedures.
- Avoid creating duplicate indexes
- Delete unused indexes
- Construct SQL based on existing indexes
- Build new indexes that application desperately needs
One of the worst things that you can do, from a performance standpoint, is to completely forbid the creation of any new logical files on your system. You may have existing physical files with hundreds of logicals which seems completely out of control. Even in this scenario, there may be completely justified reasons for creating more. The performance implications of not having a needed index for a heavily used access path can be tremendous.
There are significant consequences of too many logical files as well - especially if many of them are unused, duplicates or 'near duplicates'. Maybe the most important point here is an understanding of a 'near duplicate'. If you have three logical files keyed ascending as follows:
- FIELD1
- FIELD1, FIELD2
- FIELD1, FIELD2, FIELD3
This is what we mean by 'near duplicates'. The third index is the only one that is technically needed. The others are redundant and a waste of system resources.
How do we identify duplicate indexes?
You can start with the DSPDBR command. You must specify the name and library for a physical file on your system. Remember, this is where the data is stored. This command will show you all of the 'Dependent Files' that exist, regardless of the library they reside in. These files are the logical files or indexes that provide alternate sequences or views of the physical data.
Now that the indexes are identified, use the DSPFD command on each of them to display their 'Access Path Description'. Don't forget about the physical file. It may have a keyed access path or index as well. Each 'Key field' and 'Sequence' needs to be recorded for all of the access paths. Once this information is collected, you may find exact duplicates or some 'near duplicates' as described earlier. Application software changes may be necessary before any of these can just be deleted.
How do we identify unused indexes?
Use the DSPDBR and DSPFD commands as described earlier on each physical and logical file of concern. Record the 'Creation Date', the 'Last Used Date', the 'Days Used Count' , the 'Data Space Activity Statistics' and the 'Access Path Activity Statistics' for each file.
All 'Activity Statistics' reflect file usage since the last system IPL. This information is helpful in identifying unused indexes, but you must take into consideration when your last system IPL occurred.
If you find files with no last used date, no days used count and no activity statistics - there is a good chance that this is an unused index. You may find files with some usage but no recent activity. It is important to note that some operating system save and restore operations may reset an objects last used and days used attributes.
How can I force an SQL request to use an existinglogical file or index?
You can not force it - you can encourage it. If you specify the name of a logical file in an SQL request, you are actually making the system work harder to fulfill the request. The operating system needs to know the name of the physical file. If you tell it a logical file, it needs to figure out the name and location of the physical.
Once the physical file is known, the operating system goes through a similar process to what we described earlier. It looks at the key fields of all dependent files on the system and attempts to find an existing index matching the fields in the WHERE clause of the SQL request. This is called query optimization and the building of an access plan. The operating system determines on its own what index to use based on its optimization logic and the syntax of the SQL provided.
We have recently added a section to the Workload Performance Series menu called 'New Features'. Option '15. Database Relations' from the 'EZRAD WORKPERF' menu is one of our latest new features that helps significantly with the data collection described in this issue of Performance 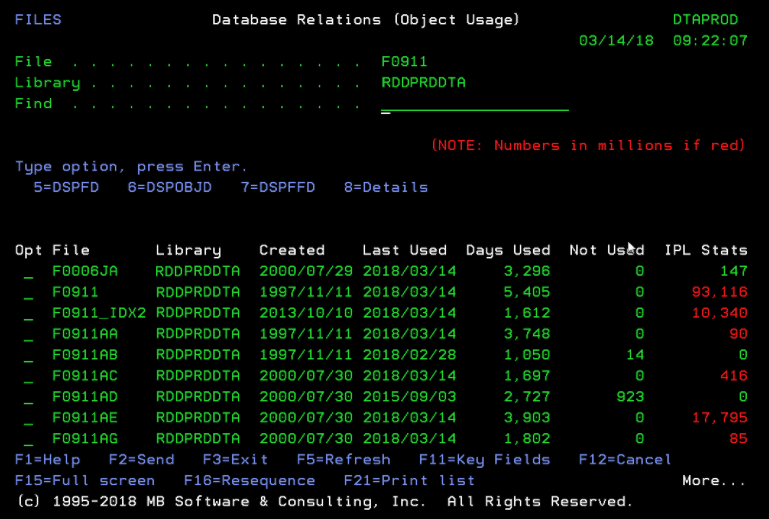 PLUS.
PLUS.
This new option prompts you for a file and library name. You can specify the name of a physical file or a logical file. If a logical is entered, we figure out the name of the physical and use the DSPDBR and DSPFD commands automatically. All data described earlier for finding duplicate and unused indexes is gathered together into our interactive 'Database Relations' screens.
In addition to showing 'Days Used', which is based on the 'Created' date - we calculate and show the days 'Not Used' which can come from the 'Created' or the 'Last Used' dates.
The 'IPL Stats' column is an accumulation of all relevant 'Activity Statistics' from the DSPFD command. If a file has 'IPL Stats' but no usage date or days - it is a duplicate index. The duplicate object is not used but it has 'Access Path Activity Statistics'. This means that it is sharing an access path with the used/duplicate index. Use the 'F11=Key Fields' function key to compare the key field names and sequence of these duplicates.
Our Disk Navigator tool can be used to identify the largest physical and logical files on the system. These files would be a good place to start when looking for duplicate and unused indexes. You can also use the 'Disk Activity Statistics' features of this tool to pinpoint the indexes with the most and with the least I/O activity. The goal here is to identify and prove that many existing indexes are unnecessary.
Now let's use our Query Optimizer tool to find those new indexes that your application desperately needs. Performing full table scans thousands of times per day over the same file does not lead to good system performance.